
真·地表最强:蓝厂带着发哥,支棱起来了
 从极客湾放出的Geekbench 5 CPU跑分显示,天玑9200多核跑分为4459分,比天玑9000有一定提升,不过,极客湾测试使用的是工程机,分数仅供参考。从CPU多核性能看,整体略强于苹果A14水平,距离A15和A16还有一定距离。
从极客湾放出的Geekbench 5 CPU跑分显示,天玑9200多核跑分为4459分,比天玑9000有一定提升,不过,极客湾测试使用的是工程机,分数仅供参考。从CPU多核性能看,整体略强于苹果A14水平,距离A15和A16还有一定距离。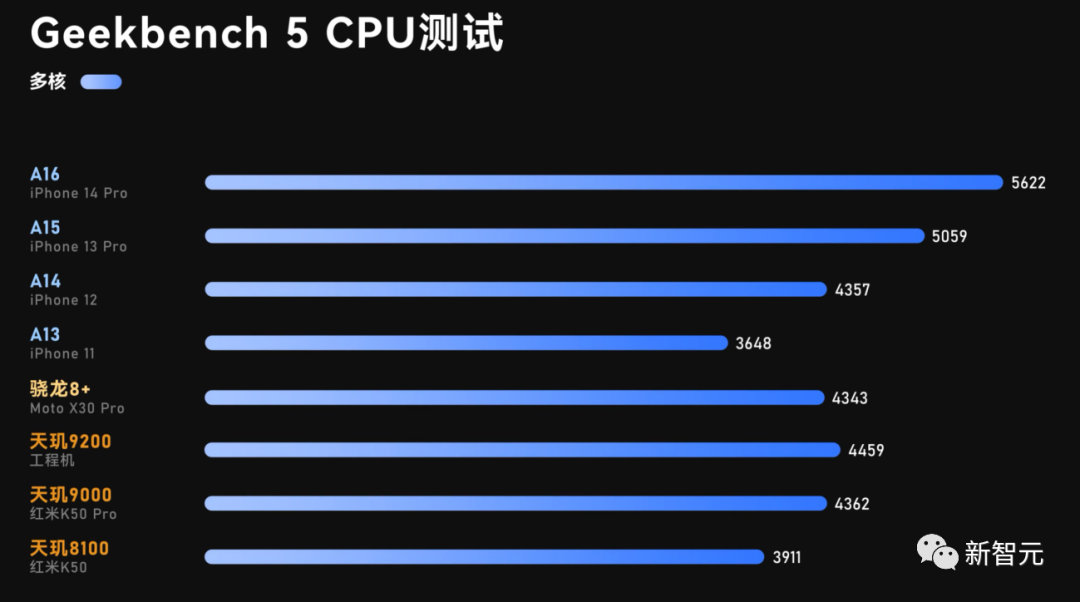

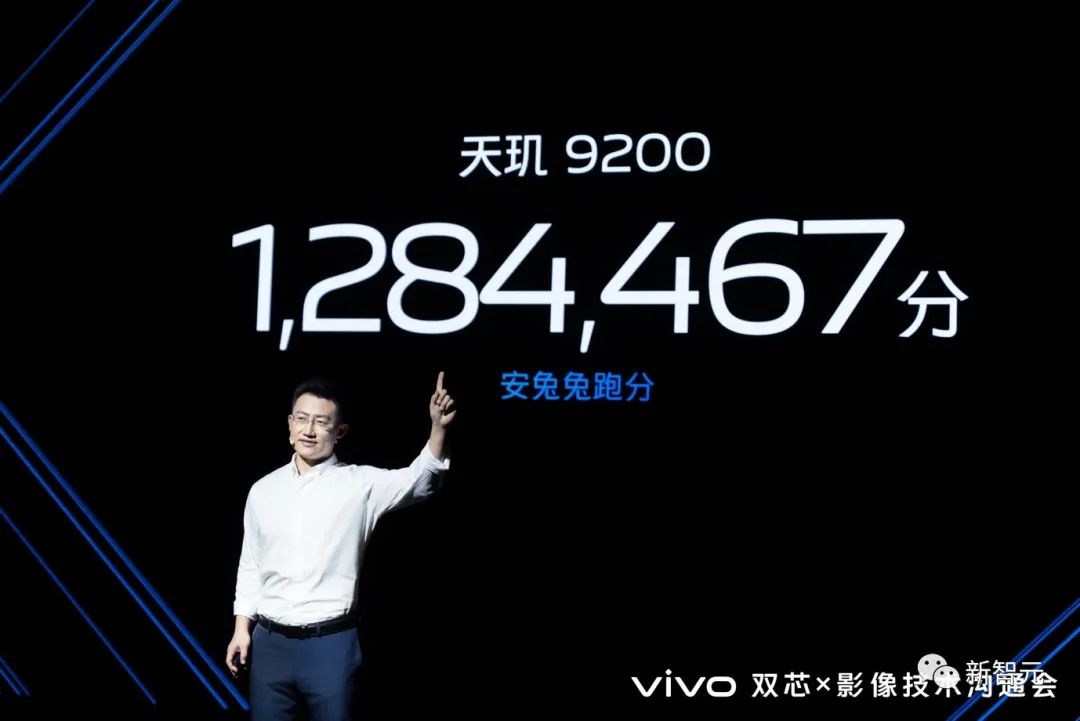 而且,无论是哪个,都击败了内置苹果M1芯片(跑分为125万)的苹果iPad Pro。真就是,发哥战未来?
而且,无论是哪个,都击败了内置苹果M1芯片(跑分为125万)的苹果iPad Pro。真就是,发哥战未来?连架构都改?自研芯片叒升级
 要实现这一点,就需要深入底层技术,甚至对芯片的架构「动刀」。对于手机AI计算而言,大致可分为平台和外挂两种解决方案:
要实现这一点,就需要深入底层技术,甚至对芯片的架构「动刀」。对于手机AI计算而言,大致可分为平台和外挂两种解决方案: FIT的原理其实很简单,首先需要把大型复杂算法模块进行拆分。然后,把算力密度小、网络结构复杂的小模型部分,通过软件部署在平台NPU上。同时,把算力密度大、数据吞吐密集的大模型部分,部署在自研芯片V2硬件上,让其中的三个单元处理各自擅长的运算内容。最终,实现了在1/100秒内完成双芯互联同步的高速协同计算。
FIT的原理其实很简单,首先需要把大型复杂算法模块进行拆分。然后,把算力密度小、网络结构复杂的小模型部分,通过软件部署在平台NPU上。同时,把算力密度大、数据吞吐密集的大模型部分,部署在自研芯片V2硬件上,让其中的三个单元处理各自擅长的运算内容。最终,实现了在1/100秒内完成双芯互联同步的高速协同计算。 而FIT双芯互联的最直接应用,就是vivo最擅长的计算摄影了。由于传统ISP的滤波器普遍是手工设计的,虽然能以极低延时处理大量的数据流水,但是只能解决已知的、特定的问题。那么对于那些复杂、未知的问题来说,最好的解决方案就是救助于人工智能。但是,当你把AI软件算法部署到NPU上时,就需要以帧或块为单位进行处理信号。相比之下,传统的ISP却是以行为单位。与此同时,由于绝大部分平台SoC片上SRAM容量有限,大量AI算法在接入ISP 管道后,要通过外部DDR来完成数据暂存和交互。这就会造成运算与数据分离,牺牲了高性能AI运算至关重要的Data-Locality要求,进一步降低了性能。为了解决这一问题,vivo在自研芯片V2上,把传统的ISP架构升级为AI-ISP架构。进而通过FIT双芯互联,第一次将平台ISP-NPU与自研芯片V2的ISP-DLA作为一个整体,设计出了目前来说最合理的AI算法处理架构。而这,也是在异构多芯片计算方向上,迈出的至关重要的第一步。
而FIT双芯互联的最直接应用,就是vivo最擅长的计算摄影了。由于传统ISP的滤波器普遍是手工设计的,虽然能以极低延时处理大量的数据流水,但是只能解决已知的、特定的问题。那么对于那些复杂、未知的问题来说,最好的解决方案就是救助于人工智能。但是,当你把AI软件算法部署到NPU上时,就需要以帧或块为单位进行处理信号。相比之下,传统的ISP却是以行为单位。与此同时,由于绝大部分平台SoC片上SRAM容量有限,大量AI算法在接入ISP 管道后,要通过外部DDR来完成数据暂存和交互。这就会造成运算与数据分离,牺牲了高性能AI运算至关重要的Data-Locality要求,进一步降低了性能。为了解决这一问题,vivo在自研芯片V2上,把传统的ISP架构升级为AI-ISP架构。进而通过FIT双芯互联,第一次将平台ISP-NPU与自研芯片V2的ISP-DLA作为一个整体,设计出了目前来说最合理的AI算法处理架构。而这,也是在异构多芯片计算方向上,迈出的至关重要的第一步。 从结构上来看,V2的可以分为三个部分:
从结构上来看,V2的可以分为三个部分: 具体来说,对于移动端的AI处理,有三个相互关联且共同决定能力上限的要素——算力容量,算力密度和数据密度。平台SoC算力容量大,适合部署网络结构复杂的模型,但能效比不高,无法满足对大密度AI运算的需求。于是,vivo在自研芯片V2的设计中,加入了近存深度学习加速器(DLA)。其中,近存DLA通过全硬化MAC设计和大容量专用片上SRAM,强化算力密度和数据密度,从而释放算力容量的潜力。
具体来说,对于移动端的AI处理,有三个相互关联且共同决定能力上限的要素——算力容量,算力密度和数据密度。平台SoC算力容量大,适合部署网络结构复杂的模型,但能效比不高,无法满足对大密度AI运算的需求。于是,vivo在自研芯片V2的设计中,加入了近存深度学习加速器(DLA)。其中,近存DLA通过全硬化MAC设计和大容量专用片上SRAM,强化算力密度和数据密度,从而释放算力容量的潜力。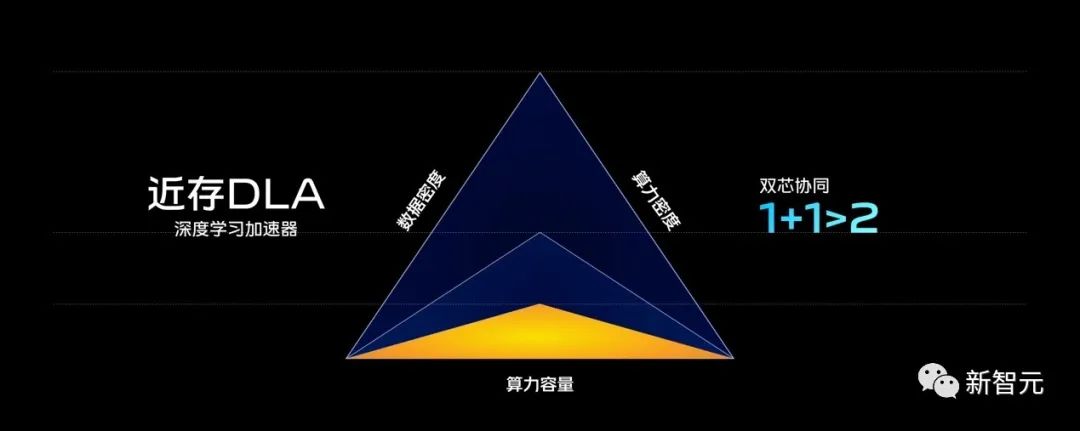 在算力密度上,得益于全硬化MAC设计,V2的近存DLA在实际AI运算中,能够达到100% MAC利用率。相比在平台SoC软件部署AI运算,8bit算力密度提升了2-3倍。此外,vivo还针对专业视频的10bit处理需求,在自研芯片V2中专门硬化了10bit的MAC单元——相比平台SoC软件部署所采用的合并运算方式,10bit算力密度提升了4-6倍。
在算力密度上,得益于全硬化MAC设计,V2的近存DLA在实际AI运算中,能够达到100% MAC利用率。相比在平台SoC软件部署AI运算,8bit算力密度提升了2-3倍。此外,vivo还针对专业视频的10bit处理需求,在自研芯片V2中专门硬化了10bit的MAC单元——相比平台SoC软件部署所采用的合并运算方式,10bit算力密度提升了4-6倍。 另一方面,数据密度受到传统架构von Neumann内存墙的制约,大密度运算会遇到数据填喂不足、运算等待数据的问题,极大限制了计算性能。为保证数据密度与算力密度的完美匹配,自研芯片V2在近存DLA内配套设计了速度高达1.3万亿bit/s的专用片上SRAM,并把容量提升到了等效45MB,比前一代的V1大了40%。这种近存DLA的设计,大幅减少了数据寻址和搬运的功耗,与通常NPU采用的DDR外存设计相比,SRAM数据吞吐功耗理论最大可减少99.2%。
另一方面,数据密度受到传统架构von Neumann内存墙的制约,大密度运算会遇到数据填喂不足、运算等待数据的问题,极大限制了计算性能。为保证数据密度与算力密度的完美匹配,自研芯片V2在近存DLA内配套设计了速度高达1.3万亿bit/s的专用片上SRAM,并把容量提升到了等效45MB,比前一代的V1大了40%。这种近存DLA的设计,大幅减少了数据寻址和搬运的功耗,与通常NPU采用的DDR外存设计相比,SRAM数据吞吐功耗理论最大可减少99.2%。 算力密度和数据密度的双重提升,以及多项低功耗电路设计方法的加持,让自研芯片V2的近存DLA在同等芯片制程条件下的表现远超同行竞品。也就是说,内核每瓦算力在运行8bit MAC和10bit MAC时,分别达到了16.3TOPS/W和10.4TOPS/W。
算力密度和数据密度的双重提升,以及多项低功耗电路设计方法的加持,让自研芯片V2的近存DLA在同等芯片制程条件下的表现远超同行竞品。也就是说,内核每瓦算力在运行8bit MAC和10bit MAC时,分别达到了16.3TOPS/W和10.4TOPS/W。 如此一来,在部署相同算法时,自研芯片V2相比传统NPU,能效比提升了200%。不出意外的话,在全新的AI-ISP架构下,配合FIT双芯互联、近存DLA、专用片上SRAM等多项突破性设计,全新的V2又会让手机计算摄影再次「起飞」。
如此一来,在部署相同算法时,自研芯片V2相比传统NPU,能效比提升了200%。不出意外的话,在全新的AI-ISP架构下,配合FIT双芯互联、近存DLA、专用片上SRAM等多项突破性设计,全新的V2又会让手机计算摄影再次「起飞」。给我翻译翻译什么叫「专业摄影」
说到效果,也是显而易见:长焦不抖了,暗光不糊了,就连按快门也没延迟了。要知道,专业相机的快门延迟在30ms左右,而手机的快门延迟一般在170-300ms。结果就是,同时按下的快门,相机都出完片了,手机这边可能还没开始曝光。于是,vivo全面优化了图像处理管线,通过提升Sensor启动速度,将快门延迟低到了专业相机的30ms。 手机长焦拍摄通常存在两个问题:拍摄倍率过大时画面会模糊(拍不清)、手持运镜导致画面剧烈抖动(拍不稳)。为此,vivo借鉴科研领域天文望远镜和高端显微镜的图像处理流程,带来全新的超清画质引擎。超清画质引擎从底层改写了ISP图像处理链路,将图像处理AI化,包含了Denoise降噪、Demosaic细节恢复、Deblur去模糊三大重要模块,以及蔡司光学超分算法。
手机长焦拍摄通常存在两个问题:拍摄倍率过大时画面会模糊(拍不清)、手持运镜导致画面剧烈抖动(拍不稳)。为此,vivo借鉴科研领域天文望远镜和高端显微镜的图像处理流程,带来全新的超清画质引擎。超清画质引擎从底层改写了ISP图像处理链路,将图像处理AI化,包含了Denoise降噪、Demosaic细节恢复、Deblur去模糊三大重要模块,以及蔡司光学超分算法。 其中,核心便是vivo和蔡司联合研发的蔡司光学超分算法。这套算法,能根据每个手机的模组特性做建模分析,通过逆运算动态调整,补偿光学信息,突破镜头工艺的上限。在蔡司光学超分算法的加持下,5倍以上的焦段,拍摄解析力最高提升35%。
其中,核心便是vivo和蔡司联合研发的蔡司光学超分算法。这套算法,能根据每个手机的模组特性做建模分析,通过逆运算动态调整,补偿光学信息,突破镜头工艺的上限。在蔡司光学超分算法的加持下,5倍以上的焦段,拍摄解析力最高提升35%。 在应对「手抖」方面,就到了Ultra Zoom EIS出场的时候了。这项技术包含了IMU(惯性测量单元)、OIS光学防抖与EIS电子防抖三大模块。其中,IMU负责检测抖动,OIS/EIS负责抵消抖动,软硬协同防抖。如此一来,手机就能在20X以上倍率实现抖动抵消,让被摄主体在画面中趋于平稳不会晃动。
在应对「手抖」方面,就到了Ultra Zoom EIS出场的时候了。这项技术包含了IMU(惯性测量单元)、OIS光学防抖与EIS电子防抖三大模块。其中,IMU负责检测抖动,OIS/EIS负责抵消抖动,软硬协同防抖。如此一来,手机就能在20X以上倍率实现抖动抵消,让被摄主体在画面中趋于平稳不会晃动。 为了确保在暗光场景下也能实现这样的能力,vivo做了多个算法的叠加,在手机摄影的全链路上都进行了大幅优化。首先,vivo和Sensor厂商深度合作,将Sensor ISO高感从上一代的16000提升到102400,暗光场景下的感光能力大幅提升。
为了确保在暗光场景下也能实现这样的能力,vivo做了多个算法的叠加,在手机摄影的全链路上都进行了大幅优化。首先,vivo和Sensor厂商深度合作,将Sensor ISO高感从上一代的16000提升到102400,暗光场景下的感光能力大幅提升。 其次,在运动抓拍时采用运动自适应多帧融合技术,一次快门生成多帧运动画面,叠加vivo自研的RawEnhance2.0算法,可以把每一帧有用信息叠加在一起,让暗光运动也无拖影。结果就是,在5lux的暗光环境下,画面的细节表现提升17.3%的同时,噪声降低了46%。
其次,在运动抓拍时采用运动自适应多帧融合技术,一次快门生成多帧运动画面,叠加vivo自研的RawEnhance2.0算法,可以把每一帧有用信息叠加在一起,让暗光运动也无拖影。结果就是,在5lux的暗光环境下,画面的细节表现提升17.3%的同时,噪声降低了46%。 此外,vivo这类拍摄上还采用了新一代运动测量与跳跃检测算法,运动画面定格能力相较于上一代提升58%。
此外,vivo这类拍摄上还采用了新一代运动测量与跳跃检测算法,运动画面定格能力相较于上一代提升58%。
什么是产品力?我可以不用,你不能没有
「发哥」的芯片再厉害,最终的载体还是手机。而一部好用的手机,往往是芯片厂商和手机厂商精诚合作的结晶。作为一个主打年轻用户的手机厂商,这些年vivo一直在探索一个问题:年轻人用手机,最看重什么?流畅游戏、动画丝滑、光速加载、屏幕不伤眼、多任务切换不卡、拒绝「杀后台」、续航不拉胯......即使有些佛系用户的要求要低得多,但手机行业卷了这么多年,「我可以不用,你不能没有」早已成为衡量旗舰安卓机的产品力的一个基准。作为国内手机大厂之一,早在20个月之前,vivo与联发科就已经展开密切合作。双方在影像、游戏、AI、显示、通信、功耗、UX性能等多领域展开深度联合研发。 此次,双方加深合作深度,带来了5个联合研发的重磅功能:MCQ多循环队列、王者荣耀自适应画质模式、芯片护眼、APU框架融合、AI机场模式。MCQ多循环队列:多核场景,高速传输MCQ多循环队列,是业内针对未来多核场景考量,为发挥CPU极致性能,重新定义的一款全新处理引擎。MCQ最多可为CPU和UFS之间的数据交换提供8条通道传输,有效提升CPU的数据并发处理能力,让应用软件切换和后台下载唤醒更快、更流畅。
此次,双方加深合作深度,带来了5个联合研发的重磅功能:MCQ多循环队列、王者荣耀自适应画质模式、芯片护眼、APU框架融合、AI机场模式。MCQ多循环队列:多核场景,高速传输MCQ多循环队列,是业内针对未来多核场景考量,为发挥CPU极致性能,重新定义的一款全新处理引擎。MCQ最多可为CPU和UFS之间的数据交换提供8条通道传输,有效提升CPU的数据并发处理能力,让应用软件切换和后台下载唤醒更快、更流畅。 经测试,搭载MCQ技术后,随机写入速度增加了16.7%以上,安兔兔跑分近5000分,而在更多更实用的场景的体验也有明显提升——比如大型APP的安装速度。在vivo和联发科的联合开发下,天玑9200旗舰平台成为行业首个支持MCQ的平台,相信越来越多的平台会频繁使用到这一功能。
经测试,搭载MCQ技术后,随机写入速度增加了16.7%以上,安兔兔跑分近5000分,而在更多更实用的场景的体验也有明显提升——比如大型APP的安装速度。在vivo和联发科的联合开发下,天玑9200旗舰平台成为行业首个支持MCQ的平台,相信越来越多的平台会频繁使用到这一功能。 王者荣耀自适应画质模式:提升续航,控制温度该模式由vivo携手联发科、王者荣耀三方联合研发,是基于MAGT游戏自适应循环开发的一项黑科技。vivo透过平台服务,与游戏应用间的即时信息交换,游戏应用可针对信息即时逐帧调控,达到一个「自适应闭循环」。
王者荣耀自适应画质模式:提升续航,控制温度该模式由vivo携手联发科、王者荣耀三方联合研发,是基于MAGT游戏自适应循环开发的一项黑科技。vivo透过平台服务,与游戏应用间的即时信息交换,游戏应用可针对信息即时逐帧调控,达到一个「自适应闭循环」。 经实测,开启自适应模式后,在26℃环境下,在王者荣耀120+极致配置下运行1小时,游戏帧率接近满帧(119.9),均方差仅有0.92,达到了业界顶级水平。这个成绩,有点顶了。
经实测,开启自适应模式后,在26℃环境下,在王者荣耀120+极致配置下运行1小时,游戏帧率接近满帧(119.9),均方差仅有0.92,达到了业界顶级水平。这个成绩,有点顶了。 芯片护眼:实时侦测,实时降蓝光视力健康现在越来越被大家重视,护眼也成为年轻人选购手机时的重要考量因素。最伤眼的「蓝光」,自然成为了vivo想方设法要对抗的天敌。芯片在「降蓝光」上的角色至关重要。
芯片护眼:实时侦测,实时降蓝光视力健康现在越来越被大家重视,护眼也成为年轻人选购手机时的重要考量因素。最伤眼的「蓝光」,自然成为了vivo想方设法要对抗的天敌。芯片在「降蓝光」上的角色至关重要。 vivo和联发科共同在天玑 9200旗舰平台上开发的智能降蓝光技术,能够实时侦测画面的蓝光占比,通过创新性的算法并硬化成IP的方式,实时降低蓝光。让高能可见蓝光占比小于5%,色偏程度降低12%。同时,能够根据检测结果动态调整画面色彩效果,在降低蓝光的同时保证屏幕不偏色,实现了行业性突破。APU联合调优:能效骤增,优化协同天玑9200旗舰平台的第六代APU690算力高达30TOPS,能效比相较上代提升了45%。基于APU硬件特性,联发科提供了NeuronRuntime软件加速框架,vivo将NeuronRuntime底层通用能力封装到自研的VCAP异构计算加速平台中。从芯片底层到框架层,VCAP在访存处理、动态量化、指令流水线等维度实现深度优化,让算法在多个处理器之间协同调度,带来显著的能效提升。
vivo和联发科共同在天玑 9200旗舰平台上开发的智能降蓝光技术,能够实时侦测画面的蓝光占比,通过创新性的算法并硬化成IP的方式,实时降低蓝光。让高能可见蓝光占比小于5%,色偏程度降低12%。同时,能够根据检测结果动态调整画面色彩效果,在降低蓝光的同时保证屏幕不偏色,实现了行业性突破。APU联合调优:能效骤增,优化协同天玑9200旗舰平台的第六代APU690算力高达30TOPS,能效比相较上代提升了45%。基于APU硬件特性,联发科提供了NeuronRuntime软件加速框架,vivo将NeuronRuntime底层通用能力封装到自研的VCAP异构计算加速平台中。从芯片底层到框架层,VCAP在访存处理、动态量化、指令流水线等维度实现深度优化,让算法在多个处理器之间协同调度,带来显著的能效提升。 基于这套方案,vivo在APU上实现了相机超清文档、实况文本、离线语音输入法等多项应用上的性能优化。以离线语音输入法为例,vivo支持全离线语音输入,确保数据不出端,用户隐私安全不外泄。这是行业首次实现语音转换算法NPU优化落地。对比行业通用的CPU方案,功耗优化30%,性能提升50%。
基于这套方案,vivo在APU上实现了相机超清文档、实况文本、离线语音输入法等多项应用上的性能优化。以离线语音输入法为例,vivo支持全离线语音输入,确保数据不出端,用户隐私安全不外泄。这是行业首次实现语音转换算法NPU优化落地。对比行业通用的CPU方案,功耗优化30%,性能提升50%。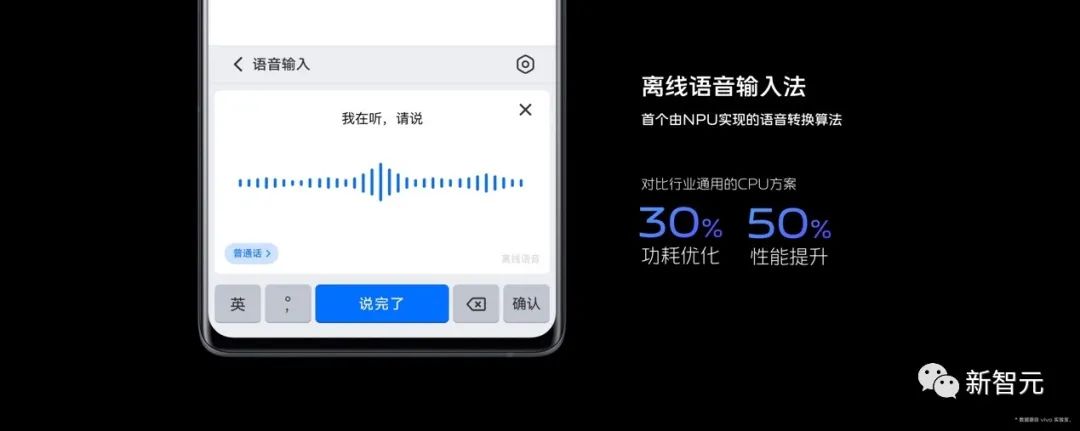 AI机场模式:飞行节能,落地速连AI机场模式包含两大AI引擎:感知AI引擎、搜网AI引擎。在这一模式下,手机通过感知AI引擎准确感知用户进入机场与飞机的起飞降落,再通过搜网AI引擎来准确识别目的地,并智能调控搜网策略。
AI机场模式:飞行节能,落地速连AI机场模式包含两大AI引擎:感知AI引擎、搜网AI引擎。在这一模式下,手机通过感知AI引擎准确感知用户进入机场与飞机的起飞降落,再通过搜网AI引擎来准确识别目的地,并智能调控搜网策略。 开启这个模式,若手机开启飞行模式,起飞后至降落前平均可以节能 30%。
开启这个模式,若手机开启飞行模式,起飞后至降落前平均可以节能 30%。 关闭飞行模式后,捕获网络的速度也大幅优化。由7.41秒缩短至1.52秒,提速79%。
关闭飞行模式后,捕获网络的速度也大幅优化。由7.41秒缩短至1.52秒,提速79%。用了30多年的底层算法,改了!
天玑9200旗舰平台的惊艳表现离不开底层的优化,vivo与联发科一道,对计算、存储等底层能力进行了内核级创新。完美适应多极限场景,4K60帧视频录制功耗大降此次,vivo与MediaTek「双芯联调」的效果首先体现在影像功能的表现上。经过双方共同优化,新平台多种拍摄场景下的表现大幅提升,并首次以极低的功耗实现了先进的循环视差网络,大幅优化能效表现,能耗降低了15%。尤其是在4K 60帧极限录像场景中,天玑9200的功耗相比天玑9000,足足降低了25%。 游戏:全流程提速,帧数稳定温度低在游戏场景下,新发布的Origin OS3不仅带来了游戏超分等「黑科技」,还通过疾速启动引擎和网络加速引擎增强游戏表现,对游戏的下载、启动、加载、运行等多个环节进行全方位优化。
游戏:全流程提速,帧数稳定温度低在游戏场景下,新发布的Origin OS3不仅带来了游戏超分等「黑科技」,还通过疾速启动引擎和网络加速引擎增强游戏表现,对游戏的下载、启动、加载、运行等多个环节进行全方位优化。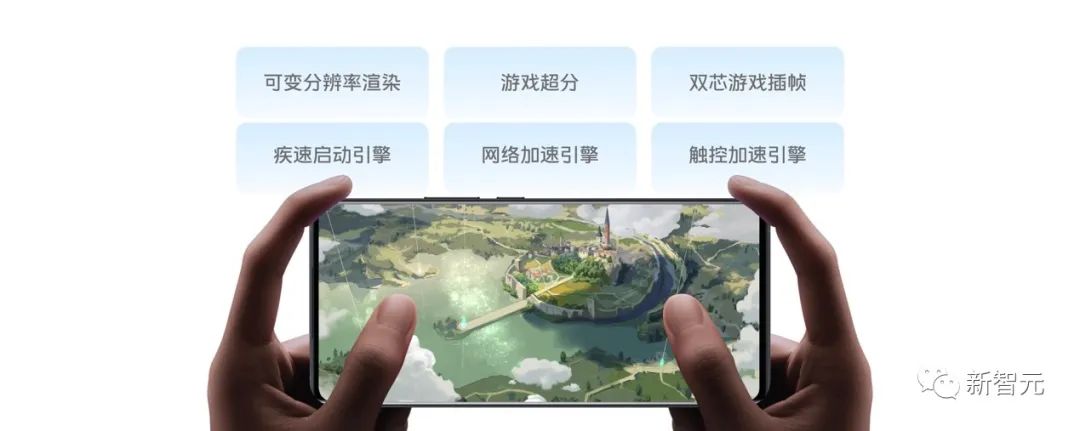 而王者荣耀在120帧+极致画质下,能接近满帧地运行1小时,就是对冷劲、全速最好的解释。
而王者荣耀在120帧+极致画质下,能接近满帧地运行1小时,就是对冷劲、全速最好的解释。研发竟要脚踏「两条船」
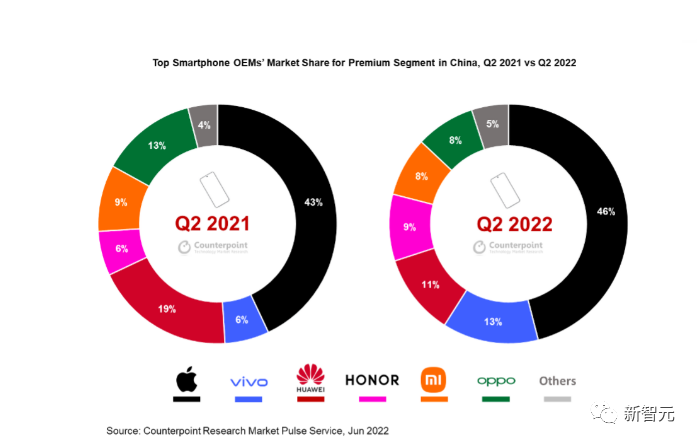
那么,自研芯片的效果到底如何呢?抛开更长远的战略不谈,就单从销量上来看,完全称得上是「效果拔群」。报告显示,2022年第二季度在X80的推动下,vivo在600美元到799美元(约合人民币4100元到5470元)区间段销量同比增长504%,vivo的整体销量同比增长91%,取代华为排到了第二位。
 不论是影像技术迭代,还是芯片架构升级,亦或是屏幕显示优化,单纯的硬件堆叠和算法配置都无法真正让人满意。实际上在去年,在vivo首颗自研影像芯片V1推出时,vivo的手机影像正式迈入了硬件级算法时代。硬件调校自然是硬件厂商的拿手绝活,为了发挥出硬件的极致潜力,vivo叫上了联发科——把自己的算法、架构固化到芯片层面,与联发科开展深度联调。vivo与联发科双方的合作,从一开始就确立了一个目标,软硬协同,实现平台性能全方面的突破。一年后,当性能和功耗同时具备惊人表现的天玑9200,遇上vivo的自研芯片,结果就是,「焕然一新」的天玑9200不仅有了更高的能效比、更快的响应速度,而且还拥有更强的游戏体验。
不论是影像技术迭代,还是芯片架构升级,亦或是屏幕显示优化,单纯的硬件堆叠和算法配置都无法真正让人满意。实际上在去年,在vivo首颗自研影像芯片V1推出时,vivo的手机影像正式迈入了硬件级算法时代。硬件调校自然是硬件厂商的拿手绝活,为了发挥出硬件的极致潜力,vivo叫上了联发科——把自己的算法、架构固化到芯片层面,与联发科开展深度联调。vivo与联发科双方的合作,从一开始就确立了一个目标,软硬协同,实现平台性能全方面的突破。一年后,当性能和功耗同时具备惊人表现的天玑9200,遇上vivo的自研芯片,结果就是,「焕然一新」的天玑9200不仅有了更高的能效比、更快的响应速度,而且还拥有更强的游戏体验。 围绕这一目标,双方都投入了精英开发团队,经过超过20个月的开发周期,大幅革新了软件通路架构,实现了1+1>2的效果。如果说,自主研发是vivo有别于他人的赛道选择,联合研发则是vivo突破技术边界的坚定尝试。与硬件厂商深度合作,走软硬件联合开发,双管齐下之路,对于构建可持续的健康生态圈、培养用户使用习惯,乃至扩展合作和产业链渠道而言,都是一种追求长远的战略布局。
围绕这一目标,双方都投入了精英开发团队,经过超过20个月的开发周期,大幅革新了软件通路架构,实现了1+1>2的效果。如果说,自主研发是vivo有别于他人的赛道选择,联合研发则是vivo突破技术边界的坚定尝试。与硬件厂商深度合作,走软硬件联合开发,双管齐下之路,对于构建可持续的健康生态圈、培养用户使用习惯,乃至扩展合作和产业链渠道而言,都是一种追求长远的战略布局。 在这方面,软硬件高度一体化的苹果,早已经走到了行业的最前头。而现在,在这条已经被无数成功验证过的道路上,出现了越来越多的前行者。vivo和联发科都知道,合作越深,步子越大,未来才有前途。正是一直以来的坚持,让vivo努力做得比别人更好,在这条路上,vivo走得比别人更踏实、更长远。
在这方面,软硬件高度一体化的苹果,早已经走到了行业的最前头。而现在,在这条已经被无数成功验证过的道路上,出现了越来越多的前行者。vivo和联发科都知道,合作越深,步子越大,未来才有前途。正是一直以来的坚持,让vivo努力做得比别人更好,在这条路上,vivo走得比别人更踏实、更长远。 来源:新智元
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
