「乱花渐欲迷人眼」,新的一天里,OpenAI 再次丢出“王炸”:ChatGPT 推出插件功能,既能联网,也能开启搜索,还能执行代码和运行计算......
一招下来,不仅把翻书、打开计算器的力都给省了,现如今还能用 ChatGPT 直接获得搜索引擎提供最新消息的体验。

代码解释器到第三方工具
OpenAI 表示,“插件是专门为语言模型设计的工具,以安全为核心原则,并帮助 ChatGPT 访问最新的信息,运行计算,或使用第三方服务。”
具体来看,其推出的插件范围包括 WolframAlpha、OpenTable、Slack 等第三方工具,以及官方推出的网络浏览器插件和代码解释器。

基于这些,普通用户也能在 ChatGPT 界面内生成代码、运行代码、上传和下载从 csv 数据到图像的文件,并评估输出结果。
除此之外,OpenAI 还开放了知识库检索插件的代码(https://github.com/openai/chatgpt-retrieval-plugin)。

网络浏览器
ChatGPT 的爆火出圈,在于它几乎“无所不能”:编代码、写策划、出小说、当客服……但作为一个基于历史数据的语言模型,ChatGPT 有个一直被诟病的问题:其训练数据截止于 2021 年 9 月,对于更新的信息数据它无法准确回答。
而今天,这道”封印“终于解除了——OpenAI 推出了网络浏览器插件,即 ChatGPT 可以联网了!
“受到过去工作的启发(包括我们自己的 WebGPT,以及 GopherCite、BlenderBot2、LaMDA2 和其他),现在我们允许语言模型从互联网上读取信息,严格扩大了其讨论内容范围,超越了训练语料库,可获得当天的最新信息。”
OpenAI 展示了一个例子,通过网络浏览器插件,ChatGPT 已可检索今年最新的奥斯卡信息:

根据 OpenAI 介绍,网络浏览器会调用 New Bing 的搜索 API 从网上检索内容,因此继承了微软在安全方面的大量工作:(1)信息来源的可靠性和真实性;(2)防止检索有问题内容的 ”安全模式“。网络浏览器可显示访问过的网站,并在 ChatGPT 的回复中引用其来源。
此外,OpenAI 明确指出该插件仅限于检索信息,不包括表单提交等”事务性“操作。它还将在独立服务器中运行,因此 ChatGPT 的浏览活动与其基础设施是区分开来的。

代码解释器(Code Interpreter)
「可以使用 Python处理上传和下载的一个实验性的 ChatGPT 模型」,这是 OpenAI 对自家最新推出代码解释器的介绍。
简单来看,OpenAI 提供了一个在沙盒、防火墙执行环境中提供工作 Python 解释器,以及一些临时磁盘空间。由代码解释器插件运行的代码在一个持久的会话中进行评估,该会话在聊天对话期间是有效的(即有上线,会超时),后续的调用可以建立在彼此之上。当前,这一功能支持将文件上传到当前的对话工作区,也能下载工作结果。
除了生成代码,代码解释器(CI)还支持的功能有:
解决数学问题,包括定量和定性的数学问题
进行数据分析和可视化
在不同格式之间转换文件
另外,OpenAI 也表示,正在邀请用户尝试代码解释器,发现其他有用的功能。
为此,国外用户 Andrew Mayne 尝试发现,代码解释器还可以分析输出并在另一个函数中使用它。这意味着你可以把不同部分的代码串起来,把一个部分的输出变成另一部分的输入。
他通过让 CI 使用一个算法来生成一个迷宫,将迷宫转换成块,使用一个算法来寻找出口,使其看起来像吃豆人,然后生成一个 GIF。

以前,当开发者使用 ChatGPT 来创建代码时,其中会涉及到把输出结果放到另一个环境中来测试。现在你可以在 ChatGPT 内做很多开发,且不需要离开用户界面。可谓极大地提高了开发者的编程效率。
通过 Andrew Mayne 的一些实测,我们不妨一起见证一下代码解释器的强大之处:
使用 OpenCV 进行人脸查找
使用 OpenCV 和一个简单的人脸搜索算法(Haar Cascade Classifier),CI 能够创建一个函数,在这张图片中找到人脸:

行星轨道
使用 Matplotlib 库,能够让 ChatGPT 模拟内行星的轨道并将其保存为 gif 图片。
创建机器学习模型
虽然 ChatGPT 不能在 CI 中加载任何机器学习库(目前),但我们可以使用 n-grams 进行一些基本的统计文本生成。在这个示例中,Andrew Mayne 给了它一本书名,要求它创建一个预测算法,然后预测文本序列中的下一个词。其结果不会很快让 GPT-4 担心,但还是很有趣。


绘图
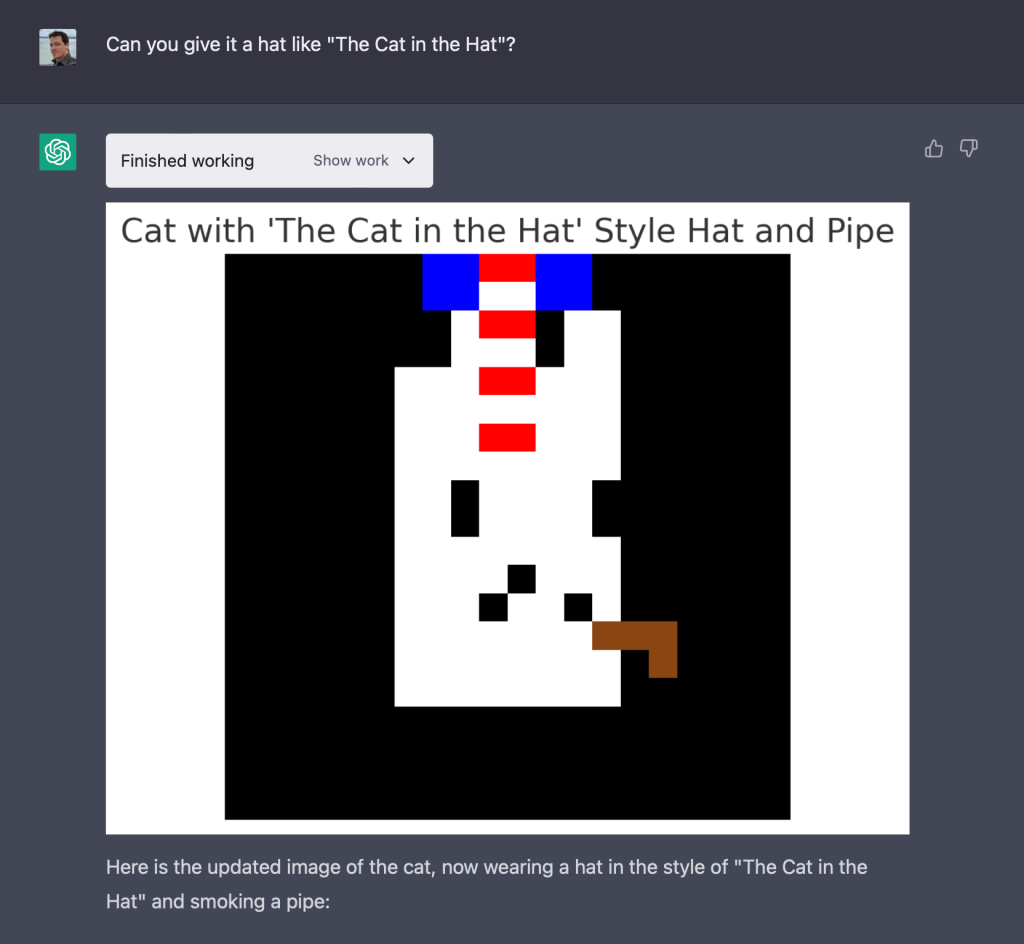
要求 ChatGPT 画一只猫,它创造了类似猫的东西。

画一只带着蓝色的高帽和嘴里有烟斗的猫。

检索
OpenAI 开源了一个 ChatGPT 检索插件(https://github.com/openai/chatgpt-retrieval-plugin),这个检索插件允许 ChatGPT 搜索一个矢量数据库的内容,比如从(Milvus、Pinecone、Qdrant、Redis、Weaviate 或者 Zilliz)作为索引搜索,并将最佳结果添加到 ChatGPT 会话中,当然前提是这些数据库内容获得了个人或组织的许可。
这样开发者可以在检索插件中添加他们被授权使用的内容,并通过自然语言提问或表达需求,从其数据源(如文件、注释、电子邮件或公共文档)获取最相关的文档片段。

第三方插件
对于第三方插件,OpenAI 表示通过候选名单的开发人员可自行为 ChatGPT 构建插件,并给出了相关步骤:
1、建立一个你希望语言模型调用的端点 API(可以是新 API、现有 API 或专门为 LLM 设计的现有 API 的包装器)。
2、创建一个记录 API 的 OpenAPI 规范,以及一个链接到 OpenAPI 规范并包括一些插件特定元数据的清单文件。
在 chat.openai.com 上开始对话时,用户可选择他们希望启用的第三方插件。关于启用插件的文档会作为对话内容的一部分显示给语言模型,使模型能根据需要调用的插件 API 来实现功能。
目前,ChatGPT 已官宣了第一批第三方插件,主要由 Expedia,FiscalNote,Instacart,KAYAK,Klarna,Milo,OpenTable,Shopify,Slack,Speak,Wolfram 和 Zapier 创建。
其中,计算知识引擎 Wolfram|Alpha 方面兴奋表示:”虽然还处于早期阶段,但这已经非常令人印象深刻——人们可以开始看到我们所谓的‘ChatGPT + Wolfram’是多么惊人地强大(甚至可能是革命性的)。”
例如,上个月问 ChatGPT 土耳其牲畜的数量时,它只会编造一个合理但错误的数据。而如今在调用了 Wolfram 插件后,ChatGPT 可以给出一个“很好且权威”的答案,并能将其可视化:


现在就能用?
基于自由的插件和第三方服务,再也不用担心 ChatGPT 胡说八道了。
OpenAI 对此也在安全与风险维度着重强调了这一点,通过整合对外部数据的明确访问——例如网上的最新信息、基于代码的计算或自定义插件检索的信息--语言模型可以通过基于证据的参考来加强其回答的质量。
这些参考资料不仅可以提高模型的效用,而且还可以使用户评估模型输出的可信度,并反复检查其准确性,从而有可能减轻与过度依赖有关的风险。
那么对于开发者及用户层面而言,什么时候能够用上?
其实自 ChatGPT、Bard、新 Bing、文心一言等大模型工具与产品发布以来,想必很多用户最怕简单的一个单词就是“waitlist”,不出所料,这一次也毫不例外(https://openai.com/blog/chatgpt-plugins)。

OpenAI 表示,目前只有一小部分用户(优先少数开发者和 ChatGPT Plus 用户)可以开始使用插件功能,其计划在了解到更多信息后,逐步推出更大规模的访问(针对插件开发者、ChatGPT 用户,以及在 alpha 期之后,希望将插件整合到他们产品中的 API 用户)。
来源:麻省理工科技评论
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
