
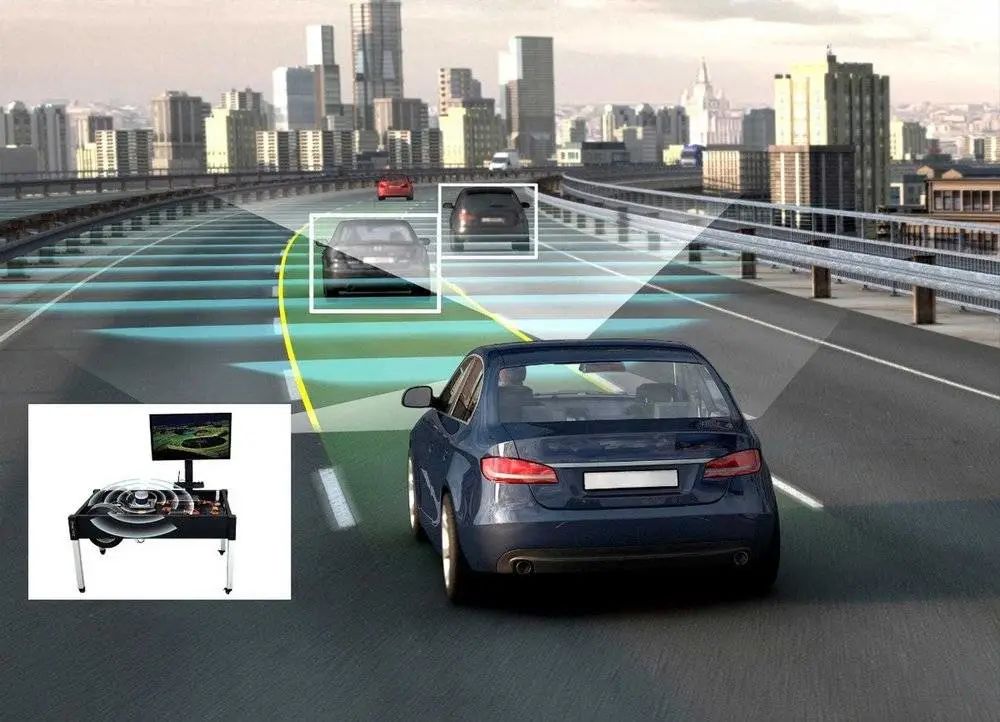
这年头,一辆智能汽车不装个激光雷达,且不吹一波智能驾驶,大概率就不好卖到25万+了。
毕竟,激光雷达、高算力芯片,以及频繁刷屏的“全程无干预”城区智驾,已经成为了一款智能汽车上最突出的溢价点。其中,前两者的硬件成本居高不下,往往只有顶配车型才会搭载。而城区智驾功能由于需要面对相比较封闭道路更复杂的交通环境,因此往往对传感器精度和算法复杂程度提出了更高要求,需要依赖激光雷达和高算力芯片来实现。
这么一看,消费者要为整套智驾软硬件动辄支付几万元,看起来确实挺合理。对此,也有不少消费者主动去选购了相应配置和方案。但问题是,这套软硬件真的能给用户带来车企宣称的价值吗?
更可气的是,不少用户在为城区智驾方案支付溢价后,却在很长一段时间内并没有得到厂商承诺的功能。
通俗而言,就是当了韭菜。
对于激光雷达,大多数车企还玩不转
正如前文所说,当前无论是BBA等德系豪华车企,还是售价20多万元的中国本土品牌,大家都将激光雷达选为了实现城区智驾的关键传感器。但就笔者的了解,尽管大家都在产品宣传页中将激光雷达作为关键卖点,但实际能让这款传感器充分发挥作用的企业并不多。
这里要解释一下,激光雷达在智能驾驶中扮演的作用。通常一辆车会搭载三类传感器:摄像头、毫米波雷达和激光雷达。其中,摄像头采集的数据为图像信息。该数据会涵盖包括道路环境、车道线、交通标志灯信息,相对而言最为全面。同时,其所需的人工智能算法也最为成熟,因此也是智能驾驶系统运行所需的主传感器。事实上,视觉识别算法也往往由车企和中国本土智能驾驶供应商所研发,迭代速度较快。
毫米波雷达的感知算法则往往由供应商提供,只输出感知结果,过程数据则不对车厂公开,也就是行业中常说的“黑盒子”。一般来说,毫米波雷达****的电磁波感知范围很远,但****角度较小,因此往往只用于探测前车速度、距离信息。但由于其抗干扰能力较强,因此对于车企来说,毫米波雷达探测到的环境信息往往仅作为视觉感知的“校验”环节,用于给视觉算法查漏补缺。
而“重头戏”激光雷达,因为其****出的激光射线构成的点云可以直观地感知到前方道路参与者的距离和位置信息,且不容易收到强光(太阳光直射)的干扰,所以被车企寄予厚望。但问题是,激光雷达的感知算法无论是对于车企还是供应商,都是前所未有的挑战。说白了,市场中的大多数玩家其实都不善于处理点云数据,并根据其感知到的结果制定驾驶决策行为。
更不用说,如何在感知环节将激光雷达的点云和摄像头的图像两种类型的数据做融合了。事实上就笔者了解,国内某家“遥遥领先”的科技公司,至今也在努力搞定这一问题。因此在实际使用过程中,车企往往也只是用激光雷达的数据和毫米波雷达一样,做校验。
笔者在这里提到的问题,并非凭空杜撰。一位在国内头部智能驾驶供应商企业供职的内部人士就告诉笔者,他们服务的客户尽管在新车上搭载了激光雷达,但由于算法研发的工程问题,前者在使用过程中甚至会对系统决策的准确性产生干扰。这就导致系统打开激光雷达后,在实际道路测试中的执行准确性甚至比之前还降低了。
对此这位内部人士表示,为了保持产品交付后质量的稳定性,他们最终在后续产品上关闭了激光雷达。也就是说,这款系统采购价格动辄上万元的高级传感器,目前只发挥了“摆设”的作用。
真不如上淘宝买个“假的”了!

事实上,一些车企们也发现了这一问题,并已经计划在后续车型产品,尤其是中端和低端车型序列中“拿掉”激光雷达。但问题是,如果没有这一传感器参与校验和“补盲”,视觉算法无法准确感知到隔壁车道中车辆的准确距离。
国内南方省份一家智能驾驶科技公司的内部人士就曾告诉笔者,他们的技术方案中已经在大部分场景里用视觉算法替代了激光雷达,但对于斜前方的“加塞车”,摄像头还是不能比激光雷达“看得更准确”,而这就为城区智驾方案带来了安全风险。

更要命的是,激光雷达理论上最好的位置是放在车顶,以获得最佳的探测角度。但问题是没有汽车企业会选择这么做,因为实在是太丑了。而像部分量产车这样,将激光雷达融入车身的做法尽管兼顾了设计美观的需求,但同时限制了其感知性能。因此,车企往往又需要更多激光雷达进行补盲,这就进一步提升了系统的复杂性,并抬高了整车售价。

不过,行业内大多数玩家搞不定的事情,并不代表着没人能做到。在全球范围内,已经有两家汽车企业在量产车上实现了依靠纯视觉算法实现城区智能驾驶功能。
这两家车企都仅仅用摄像头的视觉感知算法,实现了红绿灯通过、路口无保护左转、城区道路内的点到点智能驾驶。
其中,特斯拉的FSD
(Full Self Driving)在北美地区已经实现了交付。而在业界公认的智能驾驶难度“高地”中国,10月27日上市的极越01,则成为了“先行者”。
那么问题来了,不靠激光雷达,迄今为止最晚交付产品的新势力极越,是怎么实现了其他竞争对手都没做到的成果呢?
“占用网络”——让摄像头看到应该看到的信息作为全球唯二在量产车上实现城区智驾的车企,极越和特斯拉都在使用了BEV+Transformer 纯视觉大模型算法的基础上,加入了占用网络
(Occupancy Network)技术。这里的技术名词比较多,笔者会尽量简要地向各位解释其在智能驾驶中扮演的角色。
我们最近一年常听说的BEV,全程是Bird Eye View
(鸟瞰图)。在进行环境感知时,车企和科技公司会将车身周遭的摄像头信息进行拼接,最终实现360°的环向感知。而为了让系统进行同步处理和实时运算,工程师们将感知到的结果泛化为BEV,以便车辆进行驾驶决策。而Transformer大模型的引入,则让车辆能够根据周围环境和威胁的轻重缓急来优先处理紧迫的事项,从而在保证效率的基础上,守住安全底线。
事实上在过去一段时间内,正是BEV+Transformer技术的成熟帮助车企纷纷成功量产了高速智驾功能。但如果将使用场景放在交通环境更加复杂多变的城区道路上时,这项技术就有些不够用了。因为,相比较高速公路、城市快速路这样相对规范的封闭道路,城区道路中的交通环境参与者更加多样,大多数极端场景都发生在这里。而在过去,智能驾驶系统都是基于数据库中已经被标注过的障碍物进行决策和避让,依靠既定规则实现感知和决策BEV+Transformer就显得力不从心。
也就是说,车辆系统需要“先知道这个东西是什么”,然后再进行驾驶决策。
例如上图这样,过去的智驾系统对于道路障碍物的标注往往只能借助既有数据库的已标注信息,依靠“画方框”的方式进行。而在方框外的部分仅通过视觉算法,往往无法识别。
 简单来说,如果面对一辆完全展开作业,伸出“四脚”的工程车,智能驾驶系统可能就认不出来“它”到底是什么,进而无法进行自主决策,只能让用户接管。这一方面降低了用户的使用效率和体验,另一方面也增加了安全风险。
简单来说,如果面对一辆完全展开作业,伸出“四脚”的工程车,智能驾驶系统可能就认不出来“它”到底是什么,进而无法进行自主决策,只能让用户接管。这一方面降低了用户的使用效率和体验,另一方面也增加了安全风险。
而占用网络技术的引入,则很大程度上解决了这一问题。该算法是在传统3D目标识别能力之上,通过体素
(Voxel)化的方式理解和处理空间信息,将场景空间分割成单位化的“方块”。因此,视觉感知算法无需具体识别物体是什么,而是能够直接通过目标的体积、运动状态判断其是否构成行车路线上的障碍物。
换言之,车辆终于能像人一样,不用先“认识”目标,再进行驾驶决策。而是“看见这儿有东西”,然后调整路线。 当然,极越01身上的这一“绝技”,是基于多年技术积累而实现的。作为“背靠”百度的智能车新势力,极越一上来就拿到了百度L4级无人车的原子化能力。毕竟后者迄今为止已经积累了7000万公里的城市道路自动驾驶测试里程,为极越提供了行业内无与伦比的数据积累。而在2022年占用网络算法提出后,极越便在积极进行研发和测试,最终在今年实现了纯视觉城市智驾方案的跑通。
在谈到为何坚定选择纯视觉方案而“甩开”激光雷达时,极越CEO夏一平对笔者表示,直到今年年初,该公司还在内部纠结到底应不应该走这条路。但他基于两点原则认为,纯视觉才是正确的选择:
第一,
传感器越复杂,系统对于驾驶行为的不可控影响就会提升。用最简单直观的方案解决问题,不仅符合第一性原则,更有助于降低整车的售价和维修成本。毕竟激光雷达如果因为事故或颠簸损坏了,修起来可不便宜。
第二,
AI赋能下的纯视觉技术路线,其后续算法迭代的空间相对更大。对于这个问题夏一平没有展开说明,但根据视觉感知算法在安防、自动驾驶以及其他各个领域的广泛应用可以看出,全社会的各个经济和科技领域都在这方面投入的相当多的资源。因此相比较仅在汽车和少数领域使用的激光雷达,视觉算法未来迎来“奇点”的可能性要大得多。
在实际体验中,极越01上搭载的“PPA点到点领航辅助驾驶”功能实际表现相当令笔者感到惊艳。在上海市的城区和高速场景中,这款车的智驾功能对于红绿灯路口通过、无保护左转、上下匝道等场景均实现了无接管通过,
对于高速公路的车道变更和超车也执行得十分顺滑。已经达到甚至超越了某些搭载了激光雷达的车型。
更重要的是,极越01在上市交付时,便直接开启了PPA点到点领航辅助驾驶功能的开放使用。在上海、广州和深圳三个一线城市,选配了“ROBO Drive Max”智驾软件包的用户已经可以使用该功能。从2024年开始,极越将向全国超过200个城市的用户开放城区PPA
(点到点领航辅助)功能。也就是说,车辆能够在高速、高架和用户上下班等常用的路线上,实现点到点的城区智驾。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。


